Intro
Data is streaming into your KQL database. Either from Home Assistant or any other source. The data stream is full of issues and its hard to make full use of the capabilities of ADX/KQL. You are not satisfied with the schema, you need to do aggregations on the data all the time or their might be duplicates in your data you would like to get rid of and you do not want to write this into each KQL query. If there just was a way to get all of this work done automatically by the KQL cluster.
In the KQL we have answers to these problems, the answers are update policies and Materialized views. This blog describes when to use them and how they work. the examples provided are based on data ingestion from Home Assistant as described in this blog: INSERT BLOG LINK
After this you will have high performance views on your data, in the schema and aggregation level you desire
The Update Policy
Microsoft: “Update policies are automation mechanisms triggered when new data is written to a table. They eliminate the need for special orchestration by running a query to transform the ingested data and save the result to a destination table. Multiple update policies can be defined on a single table, allowing for different transformations and saving data to multiple tables simultaneously. The target tables can have a different schema, retention policy, and other policies from the source table.”
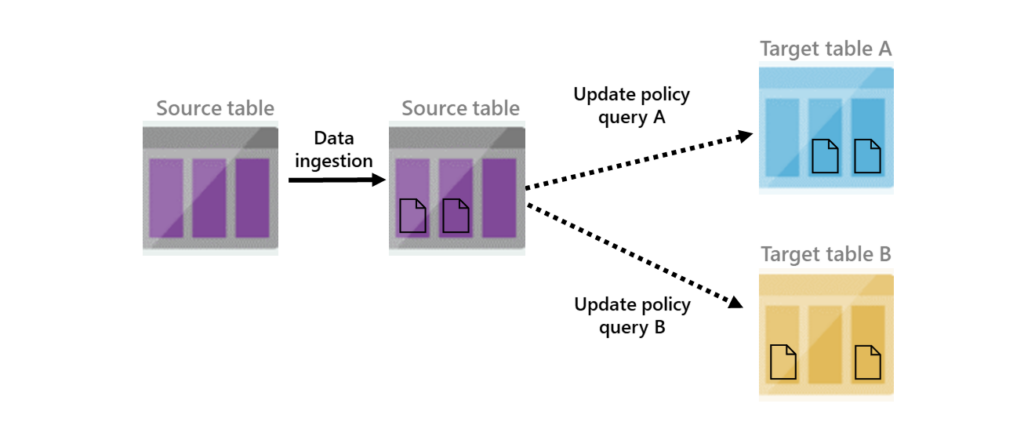
In short an update policy is a KQL query that we run on any and all newly ingested data in our source table, and the output is written to a destination table.
link to Microsoft documentation: https://learn.microsoft.com/en-us/azure/data-explorer/kusto/management/update-policy
When to use an update policy
There are many usecases for Update policies. but the main cases are:
- Schema changes – Remove/Rename columns from you source data. Add calculated columns from other fields, like extrating data from embedded json or change data types
- Joining – Join meta data from a another table. fx. add a site name to a row where you only have an Sensor ID, by a lookup into a master data table.
- Filtering – remove undesired data. based on content, geografi or any other logical test.
Creating a function
From the previous post, we have a table in our KQL database called HARAW.
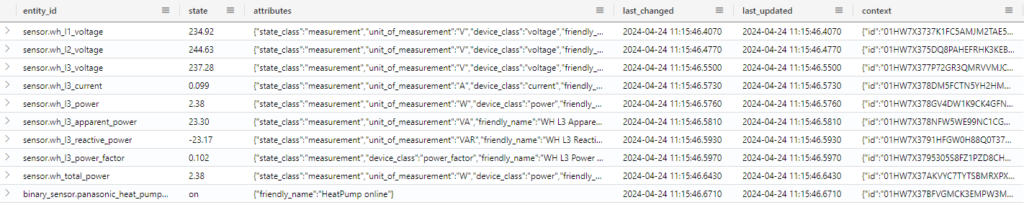
in the table we have all the information as its generated by Home Assistant, and not as we would like to have it for analytical purposes
Maybe a more appropriate schema would be something like this:
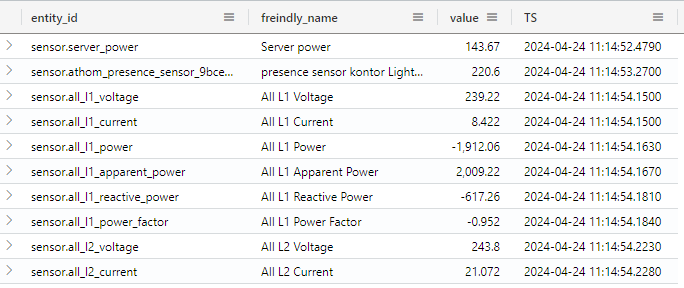
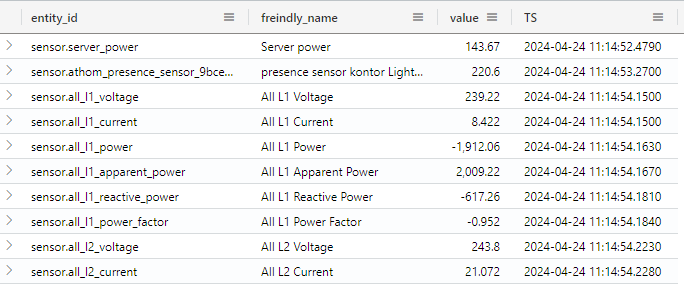
Here friendly_name is being extracted from attributes, only states with a numeric value is present, and TS is a renaming of the last_updated column. the rest of the data is removed
The query
the KQL query that will do all of the asks listed above looks like this:
HARAW
| extend value = todecimal(state)
| where isnotnull(value)
| project entity_id, friendly_name= tostring(attributes.friendly_name), value, TS = last_updatedOne important note is that when converting a non decimal value like “on” to a decimal in KQL, the output is null. so by filtering by isnotnull, only rows where the conversion succeeded are in the output.
Running the KQL on the data in HARAW provides the exact result we are interested in in this example, however your desired schema could vary a lot.
Creating an update policy
To create an update policy where we apply this transformation and filtering takes a few steps:
- Wrapping the query into a function
- Create the target table that matches the schema
- Applying the an update policy to the target table with a reference to the function
1. To wrap the the query into a function is straight forward using this command
.create-or-alter function with (docstring = "Parses raw records into numeric table",folder = "UpdatePolicyFunctions") ExtractNumeric() {
HARAW
| extend value = todecimal(state)
| where isnotnull(value)
| project entity_id, friendly_name= tostring(attributes.friendly_name), value, TS = last_updated
}This code will create a new function called “ExtractNumeric” and store it in a folder called UpdatePolicyFunctions, using the exat query described above
2. next step is to build the target table. the table can be build using the normal syntax for create table:
.create table NumericSensor (entity_id: string, freindly_name: string, value: decimal, TS: datetime) But the table can also be created diretly from the ExtractNumeric function:
.set-or-append NumericSensor <| ExtractNumeric | take 0In this case the two above statments are equal, but the first hardcodes the schema, and next step will fail if the output schema from the function does not match the schema of the new table. the 2nd statement creates the new table based on the output of the function, so they will always match.
3. Last step is to apply the update policy to the target table with a reference to the function. this is done with this command
.alter table NumericSensor policy update @'[{ "IsEnabled": true, "Source": "HARAW", "Query": "ExtractNumeric()", "IsTransactional": false, "PropagateIngestionProperties": false}]';This will enable the update policy, calling the ExtractNumeric function on all newly inserted data in HARAW, and writh the output into the NumericSensor table.
Now you can query the NumericSensor table and see its being poulated with data as data lands in the HARAW table.
hiding advanced queries behind functions
Another good use of functions in KQL is that you can create functions on top of advanced quires with a lot of logic, and by adding parameters to the function, 100 of lines in a single query can be accessed as a simple function call. this will not be described further in this blog.
The materialized view
when to use a materialized view
Microsoft: “Materialized views expose an aggregation query over a source table, or over another materialized view.
Materialized views always return an up-to-date result of the aggregation query (always fresh). Querying a materialized view is more performant than running the aggregation directly over the source table.”
In short the materialized view is a pre-aggregated table, that will give a higher performance on a query than having to aggregate data qt query time.
The main use cases are:
- de-dublication – remove dublicate data from input stream.
- Aggregation – preemptive calculate aggregated data based on the raw data, so user queries will not have to aggregate across raw data.
link to Microsoft documentation: https://learn.microsoft.com/en-us/azure/data-explorer/kusto/management/materialized-views/materialized-view-overview
Limitations and considerations
There are a number of limitations that needs to taken into perspective when using the materialized views. fisrstly they only supports a limited set of opperations, and always needs to use the sumarize keyword. also take into acount the “cost” of always having the cluste do these agregations vs. the perfomace benefits it offers. this is describe really well in the micosoft documentation linked above
Creating the materialized view
It is simple to create a materialized view
.create materialized-view NumericSensor_agr on table NumericSensor
{
NumericSensor |
summarize
Max_value = max(value),
Min_value = min(value),
Avg_value = avg(value)
by bin(TS, 1h),
entity_id
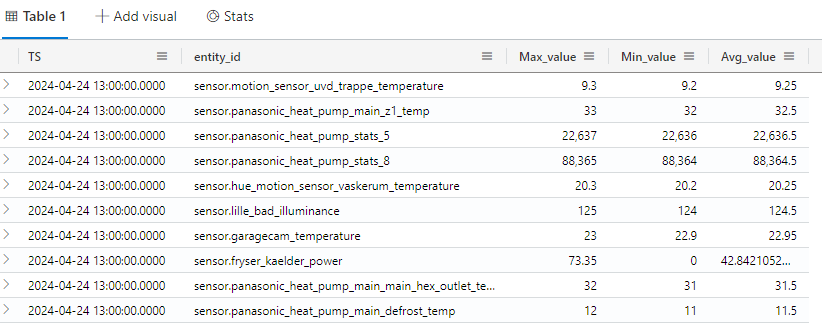
}This command will make a marterialized view with the name NumericSensor_agr that will have the maximun, minimum and average value for each entity_id for each hour.
The command do not have backfill enabled. this means that the materialization will begin only for future data. If you need to also materialize the already existing historic data in NumericSensor, the backfill option needs to be enabled:
.create materialized-view with (backfill=true) NumericSensor_agr on table NumericSensor
{
NumericSensor |
summarize
Max_value = max(value),
Min_value = min(value),
Avg_value = avg(value)
by bin(TS, 1h),
entity_id
}Using the matrialized view
The materialized view is working exatly like a normal table, and can be quried the exact same way.
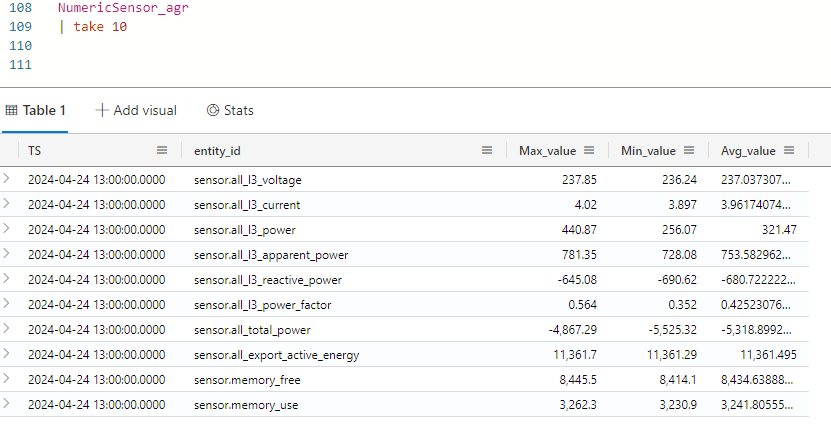
In the background the KQL engine will materialize the data in the new table. this jobs run periodically so at any given time there will be a delta of data not yet materialized. the above query will query both the already materialized data in the table, and do the aggregation on the data not materialized. This will cost some resources on query time, but give up to date answer. If you do not need the latest data, consider using the “materialized_view” syntax, that wil instruct the query only to run on the materialized data
CONCLUSION
With the use of Update policy and Materialized views in KQL we can now get the data in the shape and for as we need as well as we can get very fast results on aggregated data. and we can start using the output to create even batter and faster analytics and visuals on top of the KQL database.